python爬取熊猫关键词网站特定长尾关键词
文章摘要:利用python语言编写可以只需改变目标关键词爬就取熊猫关键词工具网站上特定关键词的长尾关键词的功能源码分享,程序使用正则匹配和BeautifulSoup两种方式去获取到长尾关键词...

长尾关键词的重要性毋庸置疑,是个有些许经验的站长们都会努力去发掘更多长尾关键词。本文就分享如何使用python语言爬取“熊猫关键词工具”网站的长尾关键词,在熊猫关键词工具网站上只要输入要一个关键词就能列出基于这个关键词的长尾关键词以及相关信息。需求多而频繁,需要每次都点开网站再输入关键词,查看,有时还需要保存下来,直接复制再整理肯定是费时的。如果使用python语言编写好采集程序,只需改变目标关键词,就能直接得到基于次关键词的长尾关键词,岂不是快哉。
废话不多说,上代码:
# 实例 爬取 熊猫长尾关键词
import requests
from bs4 import BeautifulSoup
import re
# 目标URL: https://www.5guanjianci.com/ciku/search?word=乒乓球台 以关键词“乒乓球台” 为例
headers = {'User-Agent' : 'Mozilla/5.0 (Linux; Android 4.2.1; en-us; Nexus 4 Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19'}
serchword = '乒乓球台' #目标关键词,可自定义
url = 'https://www.5guanjianci.com/ciku/search'
req = requests.get(url, params={'word':serchword}, headers=headers)
html = req.text #爬取的网页
###### 方式一 正则匹配 方式
res = re.compile(r'<tr><td><a .*?>(.*?)</a>') #正则 匹配
# 匹配形如
# <tr><td><a href="https://www.baidu.com/s?wd=室外乒乓球台&ie=utf-8" target="_blank" rel="nofollow">室外<em>乒乓球台</em></a>
keywords = re.findall(res, html)
# 匹配后 形式 的列表
# 室外<em>乒乓球台</em>
# 去除 <em> </em> 并输出
for keyword in keywords:
keyword = keyword.replace('<em>','')
keyword = keyword.replace('</em>','')
print(keyword)
###### 方式二 使用 BeautifulSoup
soup = BeautifulSoup(html, features="html.parser") # bs4 没有 html.parser 会报错
table = soup.find_all('table') #获取 表格标签
# 关键词在 每一行的第一个 即 每个tr的第一个td
table = BeautifulSoup(str(table), features="html.parser")
# 每次使用find_all查找函数 都需要新建BeautifulSoup 对象,参数是字符型
tr = table.find_all('tr') #获取每一行 后遍历
for each_tr in tr:
each_tr = BeautifulSoup(str(each_tr), features="html.parser")
td_list = each_tr.find_all('td') #每一行的 每一列 列表
if td_list: # 非空 列表
# print(td_list[0]) #第一个td即为 包含 关键词 项
# 从 td 列表里获取 标签的字符即可
print(td_list[0].text)
两种方式都能正常输出目标关键词的长尾关键词:
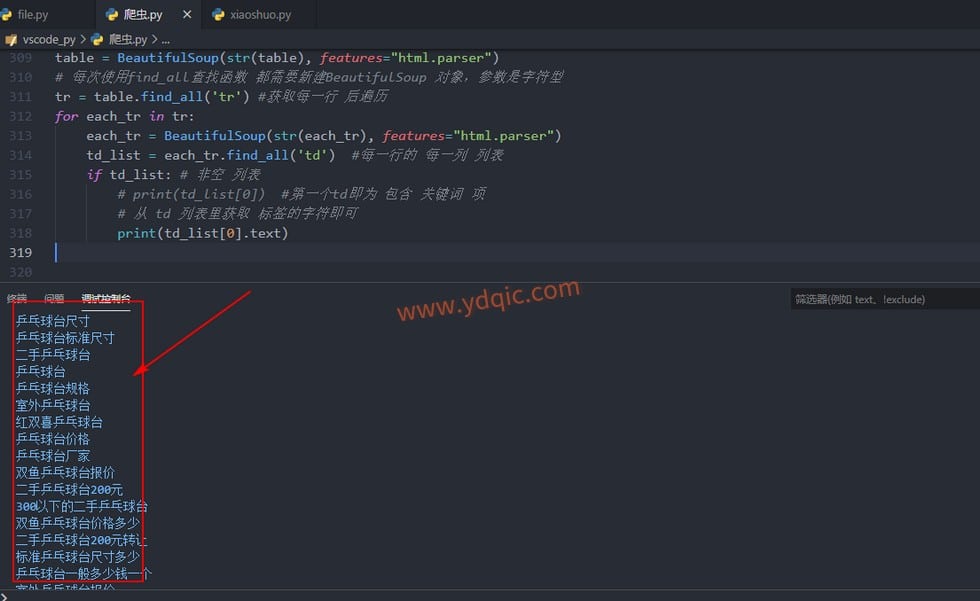
python爬取长尾关键词源码说明:
python源码,基于python3,使用到的插件有BeautifulSoup,re,requests;若运行出错,提示未安装相应插件,使用pip3 install XXX 即可,程序使用正则匹配和BeautifulSoup两种方式去获取到长尾关键词,如果是实际使用,选取一种即可;而作为学习还是都了解为好,个人觉得使用正则是十分便捷的,难点就是去理解正则表达式,比较难记,都是符号字符,很考验记忆理解能力;而BeautifulSoup对有一定HTML+CSS知识储备的人来说比较友好,有点jquery获取标签、属性的那种感觉。
代码关键点:
1、观察其网页特征,目标关键词的长尾关键词都是在表格中的每一行的第一个:
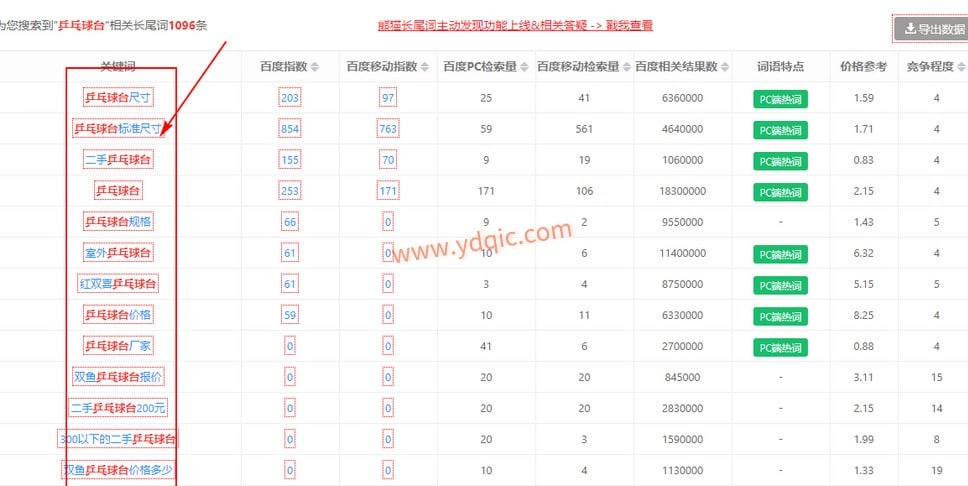
2、使用正则匹配方式时 ,主要在于处理怎么匹配到,可以网页源码其特征,如下图,其实源码里注释部分的:
<tr><td><a href="https://www.baidu.com/s?wd=室外乒乓球台&ie=utf-8" target="_blank" rel="nofollow">室外<em>乒乓球台</em></a>

3、使用BeautifulSoup时,现将表格的每一行获取到一个列表,然后遍历这个列表,得到每一行中的每一列的列表,这个列表的第一个即是包含关键词的。
版权免责申明
① 本站源码模板等资源SVIP用户永久不限量免费下载
② 所有资源来源于网络收集,如有侵权,请联系站长进行删除处理。
③ 分享目的仅供大家学习和交流,请不要用于商业用途,否则后果自负。
④ 如果你有源码需要出售,可以联系管理详谈。
⑤ 本站提供的源码、模板、插件等等资源,都不包含技术服务请大家谅解。
⑥ 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需。
⑦ 在您的能力范围内,为了大环境的良性发展,请尽可能的选择正版资源。
⑧ 网站资源绝不做任何二次加密或添加后门(原版加密除外)
① 本站源码模板等资源SVIP用户永久不限量免费下载
② 所有资源来源于网络收集,如有侵权,请联系站长进行删除处理。
③ 分享目的仅供大家学习和交流,请不要用于商业用途,否则后果自负。
④ 如果你有源码需要出售,可以联系管理详谈。
⑤ 本站提供的源码、模板、插件等等资源,都不包含技术服务请大家谅解。
⑥ 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需。
⑦ 在您的能力范围内,为了大环境的良性发展,请尽可能的选择正版资源。
⑧ 网站资源绝不做任何二次加密或添加后门(原版加密除外)
常见问题F&Q
- 需要积分的资源怎么下载?
- 您可以注册后签到等活跃动作获得积分,积分可下载,也可充值升级等级免费下载。
- 源码模板等文件安全吗?有没有后门病毒吗?
- 站内资源标有“已测试”标签的资源源码,表示已经在本地安装测试调试过才分享出来的,可以保证一定的安全;若不放心可以自行下载模板资源后使用D盾等查杀工具扫一遍确认安全。
- 本站网站模板等源码提供安装服务吗?
- 本站资源收集于网络并分享出来共同学习,不提供免费安装服务,模板源码安装等需要有一定熟悉度,小白用户可以下载资源后雇人安装调试。




